© 2025
这也是一篇 Kafka 劝退指南。我们将层层剥开 Kafka 的洋葱心:从 Log 存储结构到 ISR 复制协议,从 Zero Copy 到 KRaft 共识,彻底搞懂高吞吐背后的硬核设计。
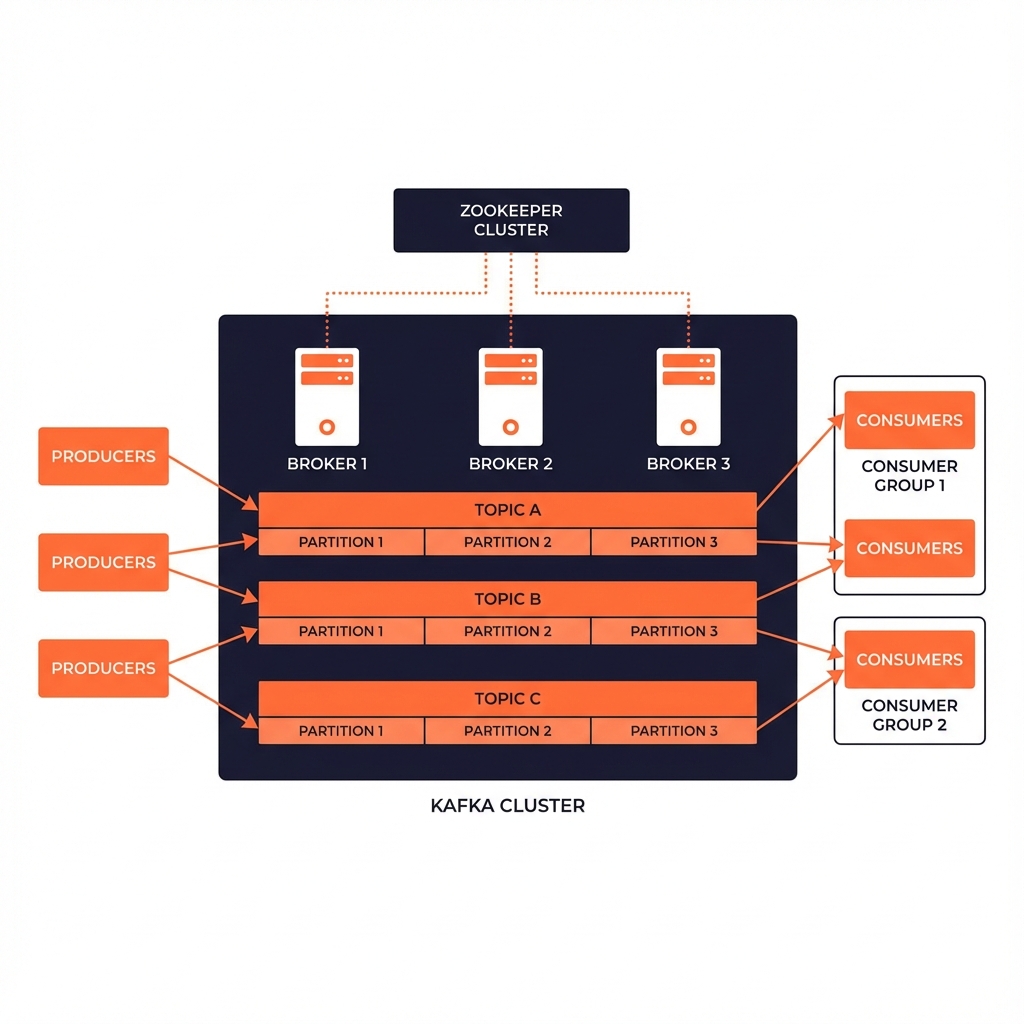
很多时候,我们把 Kafka 当作一个黑盒的 "Message Queue" 来使用。但当你试图去调优它,或者在生产环境中遇到 "消息丢失"、"Rebalance 风暴" 时,黑盒就变成了潘多拉魔盒。
这篇文章旨在打破这个黑盒。我们将分层级,从最基础的存储抽象,一直深入到分布式的共识协议,剖析 Kafka 的内部机理。
一切始于 Log (日志)。
在数据库理论中,Log 是一个仅追加 (Append-only)、完全有序 (Totally Ordered) 的记录序列。它是最简单,也是最强大的存储抽象。
传统的队列(ActiveMQ, RabbitMQ)通常设计为轻量级的:消息一旦被消费,就随风消散。 而 Kafka 的核心是 Distributed Commit Log。
graph LR
subgraph "Log Partition"
direction LR
A[Offset 0] --> B[Offset 1]
B --> C[Offset 2]
C --> D[Offset 3]
D --> E[... Append Only]
end
style E stroke-dasharray: 5 5
Kafka 的高性能,首先源于它对磁盘的极致利用。让我们看看 /var/lib/kafka/data 目录下到底有什么。
Log 并不只是一个无限长的文件(那样很难维护)。Kafka 将一个 Partition 切分成多个 Segments。 每个 Segment 包含三个核心文件:
00000000000000000000.log: 实际的数据文件。00000000000000000000.index: 偏移量索引文件(Offset Index)。00000000000000000000.timeindex: 时间戳索引文件(Time Index)。文件名是该 Segment 的 Base Offset(起始偏移量)。
为了节省内存,Kafka 的索引文件是稀疏的。它不会为每条消息都建立索引,而是每隔几 KB(默认 4KB)建立一个索引项。
查找过程 (如查找 Offset 3687):
0000..3000.log)。0000..3000.index 中找到小于等于 3687 的最大 Offset(假设是 3680,物理位置 Position 为 1024)。.log 文件的 Position 1024 开始顺序扫描,直到找到 Offset 3687。这种设计在空间占用和查找速度之间取得了完美的平衡。
对于某些场景(如 KV 存储的变更日志),我们只关心最新的值。 Log Compaction 会后台运行,删除那些 "Key 相同但 Offset 较旧" 的消息。这使得 Kafka 可以作为一种持久化的 KV 数据库使用。
Kafka 为什么能达到百万级的 TPS?因为它顺应了硬件的特性,而不是对抗它。
在机械硬盘 (HDD) 时代,随机 I/O 是性能杀手(因为磁头要跳来跳去)。但 顺序 I/O 的速度可以达到几百 MB/s,甚至超过内存随机访问的速度。 Kafka 的 Log 结构强制 Append-only,保证了严格的顺序写。
从磁盘读取数据并通过网络发送,传统路径是:
Disk -> OS Cache -> User Buffer -> Socket Buffer -> NIC Buffer
也就是:4 次拷贝,4 次上下文切换。
Kafka 利用 Linux 的 sendfile (Java FileChannel.transferTo):
Disk -> OS Cache -> NIC Buffer
也就是:2 次拷贝 (其中一次是 DMA),2 次上下文切换。CPU 全程几乎不参与数据搬运。
sequenceDiagram
participant Disk
participant PageCache as OS Page Cache
participant NIC
Note over Disk, NIC: Zero Copy Data Flow
Disk->>PageCache: DMA Copy
PageCache->>NIC: DMA Copy (via Scatter-Gather)
Kafka 甚至不管理堆内缓存(Heap Cache),而是完全依赖操作系统的 Page Cache。
单机再快也有极限,分布式才是 Kafka 的灵魂。
每个 Partition 都有一个 Leader 和多个 Follower。
Kafka 不要求所有 Follower 都同步完消息才确认提交(太慢),也不允许只要 Leader 写完就确认(不安全)。 它引入了 ISR 集合:
replica.lag.time.max.ms),会被踢出 ISR。graph TD
subgraph "Leader (LEO=10)"
L_Recs[Messages 0..9]
end
subgraph "Follower A (LEO=10)"
FA_Recs[Messages 0..9]
end
subgraph "Follower B (LEO=8, Slow)"
FB_Recs[Messages 0..7]
end
L_Recs --> FA_Recs
L_Recs --> FB_Recs
Note over L_Recs, FB_Recs: HW = min(10, 10, 8) = 8
Note over L_Recs: Consumers can only read up to Offset 8
Kafka 的消费者组(Consumer Group)是一个完全去中心化的协同系统。
当消费者上线、下线,或者 Topic 扩容时,Partition 需要重新分配。这个过程叫 Rebalance。
解决 "网络超时导致重试,从而产生重复消息" 的问题。
Producer 被分配一个 PID (Producer ID),发出的每条消息带一个 Sequence Number。
Broker 发现 SeqNum <= LastSeqNum 就直接丢弃。
解决 "Read-Process-Write" 的原子性(比如从 Topic A 读,处理,写入 Topic B)。 Kafka 借鉴了 2PC (两阶段提交),引入了 Transaction Coordinator。
isolation.level=read_committed 时,才会等待 Marker 出现,确认事务成功后再把消息吐给用户。Kafka 表面简单(Topic, Partition, Producer, Consumer),内部却是一个精密复杂的分布式数据库。 从文件系统的顺序读写,到操作系统的 Page Cache,再到分布式协议的 ISR 和 Epoch,每一层设计都在为高吞吐、高可用、高可靠服务。
理解了这些,你就不再只是一个 API Caller,而是一个能驾驭流数据的架构师。